RL finally works, unlocking a whole host of new capabilities for LMs. The idea is simple: if you can verify what success looks like, just try a bunch of different generations and reinforce the ones that do well. As some have said, it seems like the time to “build verifiers for everything we can build verifiers for.” So far, we’ve applied this paradigm to “easy-to-verify” domains like math (“do you get the right answer?”) and code (“do the test cases pass?”). But it’s not really clear how to generalize to the longer-horizon tasks we really care about—tasks that go beyond interacting with a computational sandbox to interacting with the real world, particularly with humans: doing any nontrivial job, tutoring students, or helping people with everyday tasks. In these settings, we need to teach models how to work with humans: how would a customer respond if the model said X? What kind of explanation would clear up this student’s misconception? How can a model steer people towards good outcomes?
These problems only become more relevant as models gain the raw intelligence to handle more complex tasks. Arguably, some of the hardest problems are hard to define rather than hard to solve, meaning that they require more interaction with humans, rather than more hands-off autonomy.
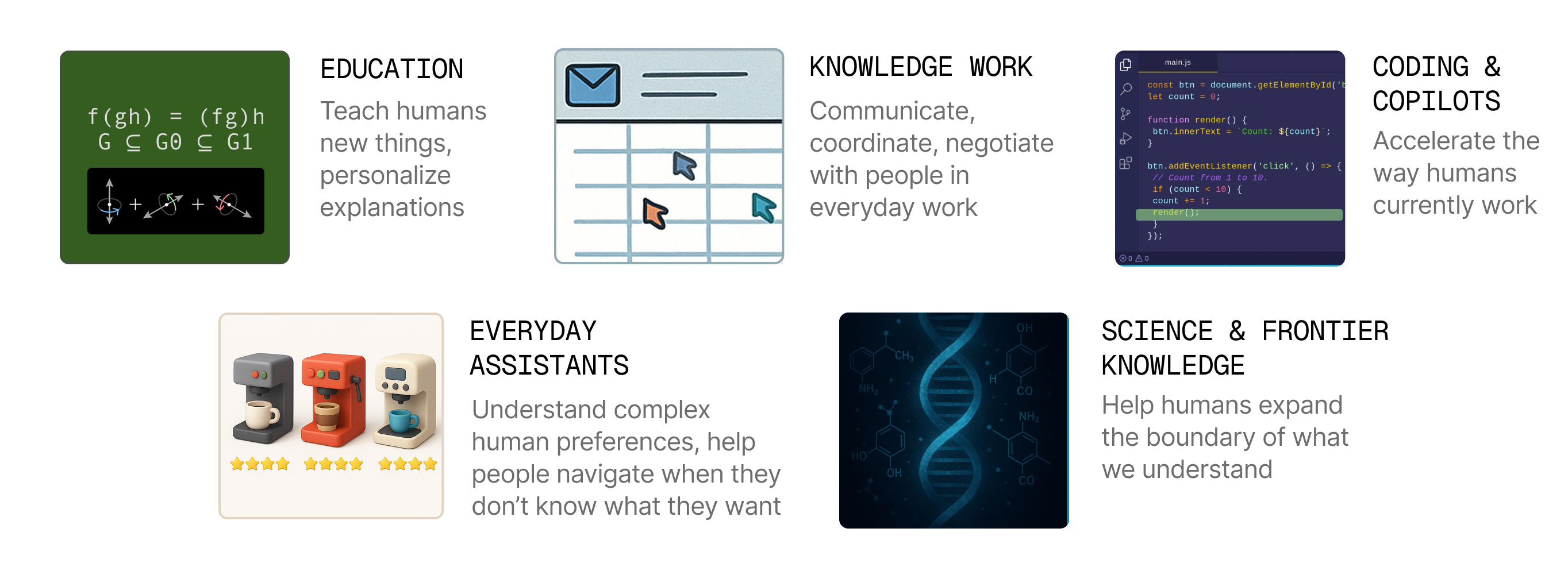
RL also becomes increasingly important as the solution paradigm. Collecting SFT trajectories of long-horizon agentic tasks is becoming prohibitively expensive (e.g. supervising models to complete week-long jobs). Just like excellent tutors, salespeople, or personal assistants learn through experience, we’d hope that agents would instead discover the right behaviors autonomously. And in the not-so-distant future, as models assist with scientific progress at the frontier of human knowledge, we need a paradigm where they can help us understand complex, novel discoveries without relying on imitation of similar human data.
To apply RL to these kinds of problems, we need to simulate environments with humans in them. A natural idea is to use other LMs to simulate humans. Perhaps we can teach models to collaborate with other models, and hope what they learn transfers to better collaboration with humans. Indeed, just like the current wave of RL for language models echoes the AlphaGo era, these ideas aren’t new: in multi-agent RL, people have trained agents against human simulators on games like Overcooked, Hanabi, and Minecraft.
A general finding from these domains is that the quality of the human simulator matters. While the challenge of SFT is data curation, the challenge of RL is environment design. For example, self-play training against a model that hasn’t been trained to be human-like only teaches the model to collaborate with other models in narrow ways, falling flat when faced with (out-of-distribution) human behavior. Language models provide much stronger priors for human behavior than we used to have, but as we’ll see, they’re still unrealistic or synthetic in important ways. RL will put optimization pressure on any unrealistic features of the user simulator. For example, if there’s a way to achieve high rewards with an adversarial prompt that coerces the user simulator model into cooperative behavior, RL (with enough scale) will discover it, even if humans wouldn’t cooperate the same way.
Collectively, we’ve worked on user simulators in the contexts of preference elicitation, decision making agents, and negotiation. This is the first post in a series sharing some of the lessons learned from our explorations into LMs as user simulators. In this post, we’ll discuss some of the non-obvious challenges of using language models as user simulators, and in the next, we’ll discuss some ways of thinking about the space of solutions. But it’s still an open question, and one of the most interesting challenges for the next frontier: how do we build realistic user simulators to train models to work with humans?
Why user simulators fail
There are some modern environments that implement user simulators: tau-bench (customer service), DialOp (personal assistants / decision-making), ChatShop (shopping), USimAgent (search), SWEET-RL (website generation), and underspecified SWE-bench (code). Typically, these benchmarks implement user simulators simply by prompting another language model to behave as a human. The prompt typically includes a specification of (1) the simulated user’s goal (“You want to exchange the size 6 Adidas for size 7…”) (2) the user’s behavior policy (“You are concise, …”). Note that the user simulator does not need to be the same model that ultimately scores the interaction as a success or failure — the reward model in code, for example, can simply be whether the final program is correct. However, the important piece is that the model needs to interact with a user to solve the task. Even without considering fuzzy and difficult-to-verify goals that users might have (a reward model problem), even just simulating the interaction with a user poses challenges (an environment design problem).
While prompting this way yields user simulators that can carry out realistic dialogues, we’ll argue that their behaviors are actually narrow and limited in important ways, leading to problems if we want to optimize against simulators to learn to better solve these tasks.
Models outperform humans
Problem 1: Models are already experts. Consider training a tutor LM against a LM acting as a “student.”

The model readily agrees to act like a beginner linear algebra student, but it’s not really confused in the same way a student would be. Offer any explanation of the theorem, and the student model immediately understands (of course, real students aren’t so easy to teach).

In fact, it might even correct the teacher if offered a subtly wrong explanation, or happily go on to prove a difficult graduate-level proof as a “beginner” student.

For RL to work, the tutor model must only be rewarded for good behavior, but if the student model is “too easy to work with,” then it’s never incentivized to discover how to offer good explanations, or navigate situations where a human student is truly confused. Human teachers have to learn to overcome this, too: expert blindness often makes it difficult for someone who’s already experienced to even remember what it feels like to not understand a concept. Education highlights an unexpected reason why LMs are bad user simulators: they already surpass average human ability in many domains. The “hole” in the user simulator, where any explanation passes the check, becomes a hole in a tutor model that is trained against it.
Problem 2. Models have perfect memory. Real humans also have limitations. For example, we can’t hold large amounts of information in working memory. An interesting tidbit is that language models substantially outperform humans at the task of next-word prediction, in large part because they are better than humans at remembering and effectively conditioning on their context windows. Human dialogue is evolved to build in redundancies.
However, this also means that to best collaborate with humans, models need to account for these limitations. A model could feasibly reason over a 10,000 line code change, but PRs typically aren’t this size for a reason 🙂 Instead, it might be more effective for coding agents or Cursor-style assistants to decompose code into pieces that best help the human verify it does what they want it to do, and perhaps even learn to guide the human sequentially through changes in a way that helps them best build a mental model of what’s happening.
Even with present-day capabilities, we can easily spin up 100 background agents to write a piece of code or search hundreds of websites, but humans are already the “bottleneck.” The limiting factor in these products is no longer the amount of information they can produce, but the amount and type of information humans can effectively consume. It’s not helpful to generate a book-length Deep Research report if the user is unable to use it effectively. This is not to mention that models will continue to make errors or sometimes fail to pursue the goal the user actually wanted. These issues make scalable oversight an increasingly important area, and one can think of user simulators as a way to enable scalable oversight in iterative settings where the model needs to interact with the user to help them understand a complex output.
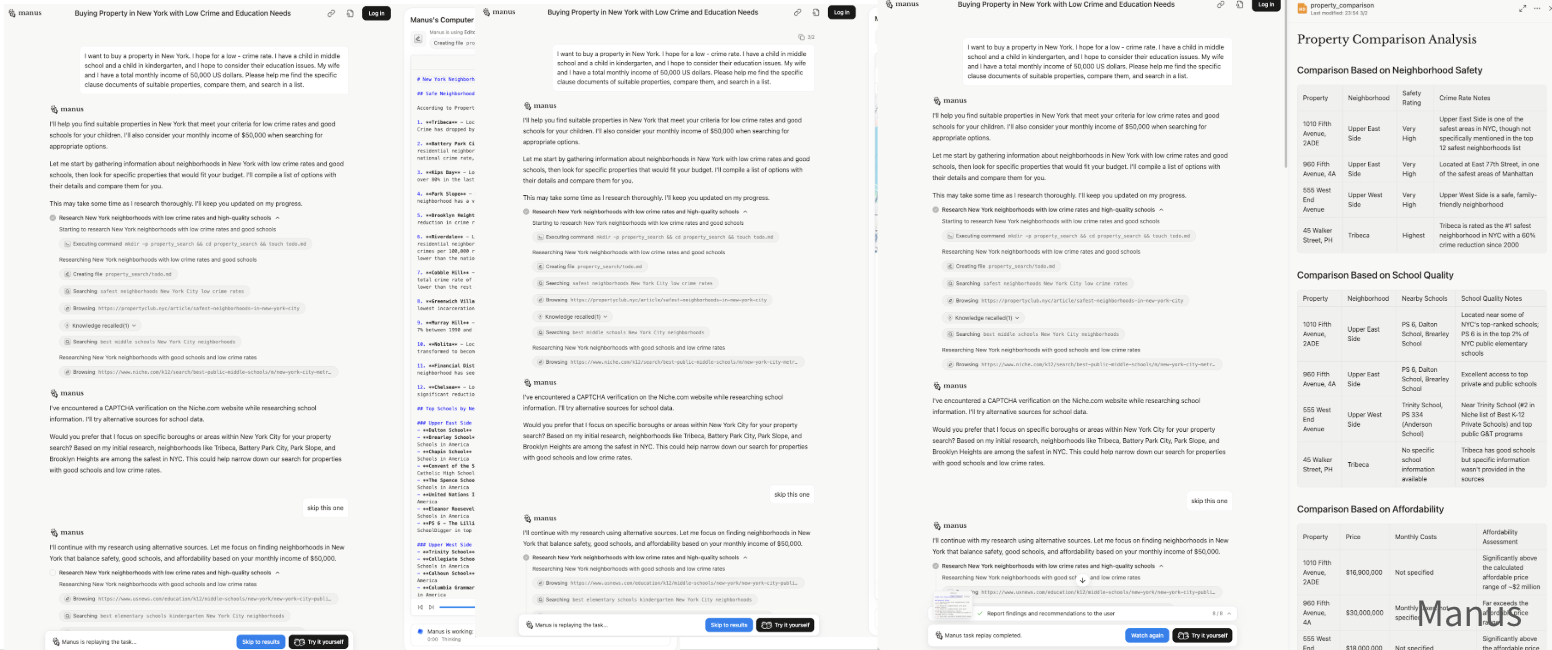
.
Problem 3. Models are too eager to comply. Part of the skill of being a good doctor is asking good questions when many patients deliberately avoid disclosing information that could actually be critical to make an informed diagnosis. There is the additional complication that people often don’t recall useful information unless prompted the right way – because a patient doesn’t have the same mental model as an expert, they may not realize that the night of insomnia they had last month is actually a relevant data point.
However, if you take a simulated “patient” LM, it helpfully spoonfeeds all the relevant information in its prompt to the other agent – “I am 45 y/o” → “I have symptoms ABC” → “I also have symptom D.” RLHF trains models to be assistants; they’re always trying hard to be helpful. For any question the doctor asks, the “patient” is eager to answer, sometimes too comprehensively. Part of the issue is that simulated users must be prompted with all the relevant context to act out a particular persona, making it difficult to simulate humans that sometimes recall useful information over the course of an interaction.
One could instruct simulated users with heuristics like “don’t say X unless asked” or “don’t answer the question directly sometimes.” However, hand-engineering heuristics like this doesn’t seem scalable, and it’s not much better than prompt-engineering the doctor LM’s behavior instead, to “ask more questions.”
We expect experts, and truly helpful models, to take initiative instead of waiting for someone to ask for exactly what they want or provide all the relevant context up front. Real humans can be uncooperative and sometimes fail to mention useful information. But without optimization pressure from the environment, it’s unlikely that language models trained in collaboration with overly helpful simulated users will generalize to unhelpful humans.
Models underperform humans
To resolve some of the problems above, one might imagine using a smaller (less capable), fine-tuned model that hasn’t been trained with RLHF and a limited context window, as a crude approximation. However, model limitations simply don’t match human limitations. The usual limitations of even the biggest frontier models also make them worse user simulators:
- Effective long-context: persona drift and degraded performance over the course of long, multi-turn interactions
- Hallucination: injecting ungrounded information, failing to accurately condition on context, not expressing uncertainty
- Diversity: failing to capture the long tail of human behavior, leading to mode collapse or regression to a bland average
We expect these kinds of problems will go away as general-purpose capabilities improve. However, there are also other limitations of current language models that are less clearly aligned with raw intelligence.
Problem 4. Models don’t have consistent knowledge or beliefs.
Do models really “believe” anything and update their beliefs in a meaningful sense? Even in the same generation, models will often say things that are obviously self-contradictory to any human (e.g. the famous recent example where a host of LMs rationalize “9.11 is greater than 9.9” for reasons like “the decimal value is larger,” despite obviously being able to explain how to compare decimals in other contexts). Instead of a set of latent beliefs, models are perhaps better conceptualized as an average “soup” of facts and behaviors from pretraining and finetuning. The 9.11 > 9.9 example is explained by the model recalling bible verses or section headers.
Humans are inconsistent too, but in predictable ways. We might compromise our stated values when faced with immediate convenience, shift our positions when presented with compelling arguments. Even apparent irrationalities can be understood, e.g. as refusing to believe things that threaten our identity. We don’t yet fully understand how model knowledge works, but on the surface they’re certainly very different from humans. Recent work has already shown that models don’t “change their minds” in an intuitive way.
This is bad news for any domain where users might change over the course of an interaction. We want user simulators to be convinced with good reasons, or understand good explanations, but the mechanism for how LMs are influenced is perhaps much more like “what mode does the context pull on in the data”? Knowledge and in-context belief updates for models aren’t as “smooth” of a manifold as we’d expect them to be.
Problem 5. “Shallow acting”: Models don’t “really want” things.
We ultimately want to build models that help humans achieve what they want. But user simulators don’t “really want” anything, unless you tell them to. Let’s say we prompt a model:

If you present the user simulator with any reasonable coffee machine and say “Reviews suggest this is a great entry-level machine…,” it’ll readily accept the choice (based on the prompt, there’s no reason not to)—much like a friend who’s buying something on your behalf but not really invested in the decision.
A quick fix is to instruct the user simulator to “be persistent” or “really try to find the best option.” But stubbornness without reason doesn’t get at the heart of the issue. When people do research, they look into second, third, and fourth alternatives because they care about a concrete outcome. Their true underlying goal is more complex than the high-level directive to “find a good coffee machine” – people imagine how annoying it would be to scrub the machine every week, or consider the risk and inconvenience of having to contact support for a replacement part. They settle on a decision when presented with good evidence that it’s the best option given the alternatives, often considering new, real-world tradeoffs (e.g. if machine A is much cheaper but harder to clean, is that worth it?). User simulators can only superficially act out the role. When we train assistants against these user simulators, we get assistants that don’t, for example, carefully probe what the user wants.
The real issue is that LMs don’t intrinsically have the same goals as the users they’re acting as. We prompt models with “Your goal is to…,” but this only leverages weak, in-context, optimization with a highly underspecified objective. Of course, this doesn’t preclude the thought that we could either (1) provide much better in-context specifications of the users we’re trying to simulate or (2) actually train models against the goals we’re asking them to pursue.
What’s needed
We’ve argued that language models don’t behave like real users, and the consequence of this fact is that current user simulators don’t lead to very good environments or reward signals for building interactive systems. Taking stock of current environments with user simulators, they mostly focus on a single, specific feature of human interaction — that users don’t say everything they want up front, and models need to iteratively extract their preferences through dialogue. For this, prompting models to “be concise” is enough. However, as we’ve seen, this misses a whole range of other behaviors we want to elicit from assistants. Every hole in a user simulator leads to interactive capability gaps in models trained against them:
| Properties of User Simulators | Consequences |
|---|---|
| Too knowledgeable | Models don’t learn how to teach humans new things |
| Too good at remembering | Models don’t optimize for efficient communication or human comprehension |
| Too helpful | Models only learn how to collaborate with helpful, high-initiative human users |
| Long-context coherence issues | Models don’t learn how to adapt to a user over the course of an interaction |
| Hallucinations | Models only selectively listen to what users say |
| Lack of diversity | Models only learn to personalize to typical or “LM-like” users |
| Lack of consistent knowledge or beliefs | Models don’t learn how to share useful information or get buy-in from people |
| “Shallow acting”, weak goal-directedness | Models only learn to help in basic ways |
Given these problems, how can we think about the fundamental ingredients we need for good user simulators? Perhaps one way to think about the basic building blocks we might need:
- Structure: some “structure” that makes the LM behave how humans generally behave (e.g. not fully stateless with everything relevant in context, but with long-term, short-term, and working memory)
- Context: enough context to control and specify to the model a specific persona to simulate
- Goal-directed behavior: enough goal-directness to simulate this person trying to do something over a long horizon
This gives some idea of how to think about approaches – which we’ll discuss in the next post.
As a final question, one might ask whether it’s really necessary to build user simulators. It seems challenging to build user simulators that are robust enough to train against, and even harder to think about how we might scale these simulated environments to train generalist models that work on any real-world problem. Besides training with real humans in the loop, it’s unclear what the alternatives are — especially if we’re serious about discovering intelligent behavior via RL, rather than large-scale supervised learning, and improving on the tasks we actually care about. Similar to robotics (another data-constrained domain), perhaps the right approach will require a combination of techniques, along with much more data-efficient algorithms. Another thought is that we likely won’t need user simulators that match human behavior fully; we may just need “partial models” that simulate the important behaviors in the context of a particular task.
If you have any ideas, let us know!
If you’d like to cite this post:
@misc{lintomlin2025usersim,
author = {Jessy Lin and Nick Tomlin},
title = {User Simulators Bridge RL with Real-World Interaction},
howpublished = {\url{https://jessylin.com/2025/07/10/user-simulators-1/}},
}