Defining the right training objective is often the key to eliciting new language model capabilities. Preference models led to more helpful assistants, and verifiable rewards led to better reasoning. But if we want to build models that can flexibly collaborate with humans to solve a wide range of complex problems, then we might need to define a new type of objective, one based on simulating real human users.
The most obvious approach involves two language models, one trained to function as a helpful assistant, and the other acting as a stand-in for a human user with a task or goal in mind. These models would generate synthetic interactions, with the user simulator judging whether or not the interaction successfully accomplished its goal. The parameters of the assistant model would then be updated based on the quality of the interaction, training in simulation to learn how to be an effective assistant.
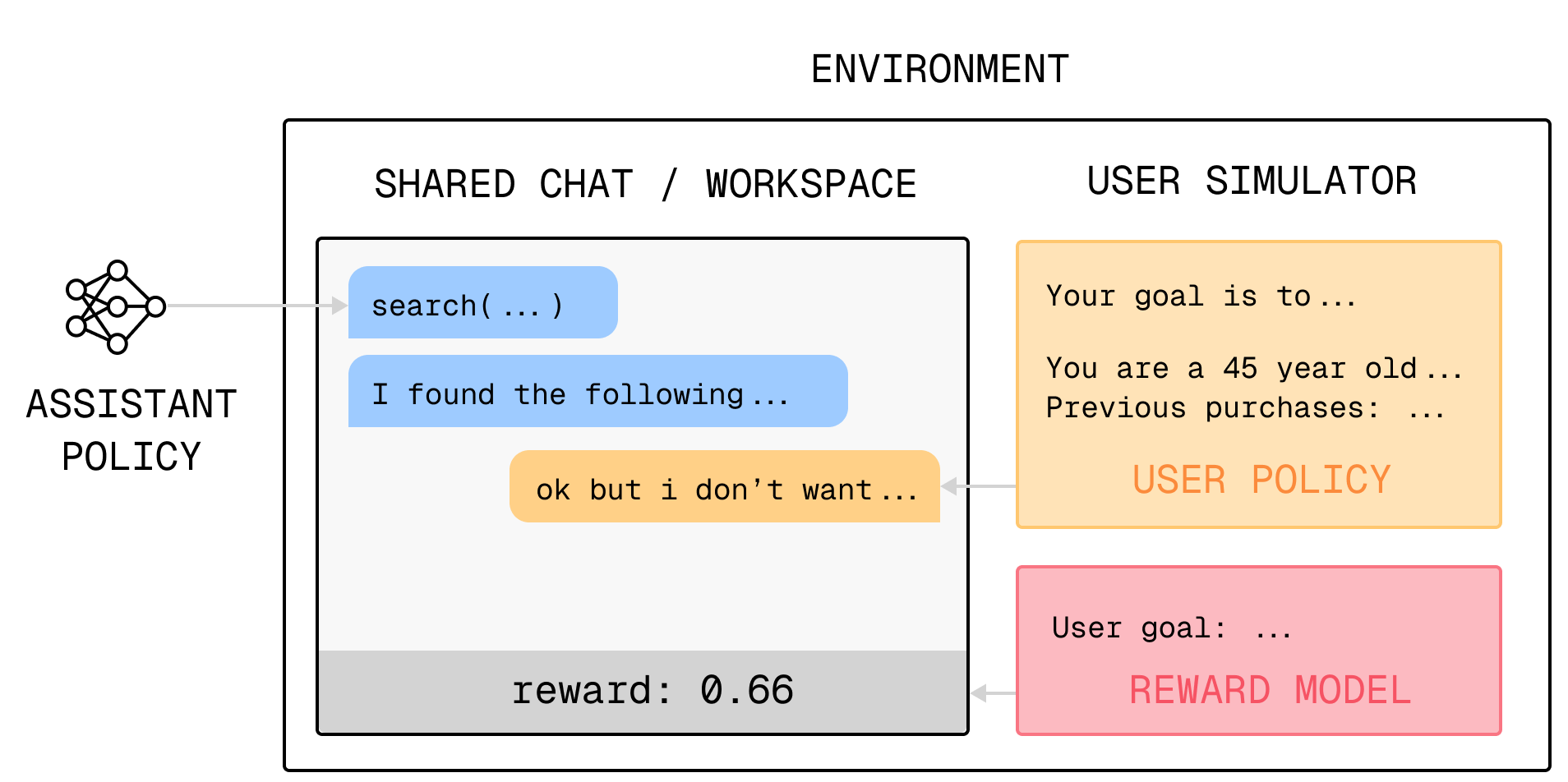
However, we still don’t know how to build effective, human-like user simulators that could be used in such a scenario. In a previous post, we discussed some of the ways that current language models fall short as user simulators. In this one, we’ll provide a framework for thinking about how to improve user simulators, and speculate on potential future approaches.
Building a user simulator requires us to make a few key design decisions: (1) the context presented to the model, e.g., how its preferences or goals are specified; (2) the scaffold, which specifies how a user simulator obtains information, interacts with the environment, and evolves over time; and (3) the objective it was trained on, whether this is the out-of-the-box language modeling objective, “helpfulness” or “human preference” in RLHF, or something more complicated. We’ll cover each of these components in turn.
Context
The first step to building more realistic simulators is to try collecting and imitating real user data. An important design decision here is what user context to condition on: how do we represent a user and get out different behaviors at inference time? Some of the essential kinds of context we might want to include:
- Goal / reward description: What is the user trying to accomplish in this interaction? e.g., “You want to reschedule your flight to the following day, if change is not possible, you want the agent to cancel and rebook” (τ-bench)
- Behavioral traits: How does the user (policy) behave, or what (task-relevant) personality traits does the assistant have to learn to interact with? To overcome the default helpful behavior, we might steer the user simulator’s behavior by specifying traits like “be concise” or “sometimes make mistakes.” We see a pretty limited range of user behavior in current work, often focused on sharing information incrementally (CollabLLM). We could imagine we’d eventually want to steer user simulators with more complex properties, such as a tendency to be indecisive, or to express confusion about a complex concept.
- Historical context: If available, including a history of user interactions or actions can implicitly specify both their goals and behaviors, as demonstrated in e.g., past chat logs or conversations with human assistants (Sierra).
Beyond these basic elements, however, one of the key problems in effective user simulation is that a lot of the context we want to condition on — beliefs, preferences, intentions, etc. — is difficult to extract explicitly from people. This makes the simulation problem highly underspecified.
For example, two people who say “I know how SVD works” often mean very different things by “know,” and it’s difficult to collect a profile that captures the user’s “true” underlying knowledge. Without this context or diverse enough data, LMs that are trained to simulate a user that “knows how SVD works” may just regress to behaving like the average user who says that. It’s important to simulate diversity in user behavior because users that say they “know” might sometimes have incorrect assumptions, or some fuzzy high-level picture that only good tutors can pinpoint by questioning the user or trying hard to discover what they actually know.
In this light, there are three directions that seem promising to push: (1) synthetic approaches to impute the latent context, (2) collecting more longitudinal data per-user, and (3) identifying new types of measurements that give us signals about a user’s latent context.
A straightforward idea if we don’t have some latent context is to synthesize it with a language model. In the spirit of recent work scaling up generative personas, we could imagine synthesizing all kinds of profiles to condition user simulators on, perhaps with more of a focus on task-relevant traits (rather than demographic or stylistic). Even better, if we have a dataset of human interactions to ground this into, we could seed or constrain data generation with real human data.
Human datasets today are relatively limited. Interaction data like WildChat at best consist of one or a few interactions with each human. Intuitively, the more context you can condition the LM on, the more you can extract “niche modes” in behavior without mode collapse. This is a case where products with users doing real tasks repeatedly, over time have leverage to build models that can directly optimize to work better with humans. With longitudinal datasets, we imagine there’d be interesting scientific questions around how much data you’d need per user to develop a good-enough user simulator to train against, for a particular task.
In general, conversations provide a limited lens into a person’s underlying beliefs and intentions. To simulate a student learning a complex topic, for example, what we’d really like is a detailed description of how exactly they think eigenvalues work. What if we just collected this data, e.g. by having them students verbalize their understanding while solving problems and using this as conditioning context for LM user simulators? Even more, we’d like to model what kinds of explanations most effectively update a student’s beliefs. When a student reads a textbook paragraph or explanation from a tutor, how does their understanding change? What problems are they now able to solve they weren’t able to before? It’s unclear yet whether LM user simulators could accurately model the evolution of a student’s responses after interventions — but if this worked, it’d be a key stepping stone to training assistant models that learn to provide the most useful interventions.
Overall, perhaps the direction to emphasize is exploring “density” and richness of human data rather than sheer quantity.
- Q1: What level of “fidelity” do user simulators need? There are many raw data streams we can imagine using as context for user simulation, all the way down to the raw stream of actions they take in their computer or IDE. However, we likely don't need to model users at this level of granularity. Intuitively, it seems useful for people to reason about other people's beliefs to some extent, but we don't need to do this perfectly to be a good assistant. What level of granularity do we need, and how do we determine the representation or abstraction that gives us the right degree of fidelity for a particular task?
- Q2: What do denser forms of data annotation look like (some ideas mentioned above: having people verbalize thoughts that are usually latent, or re-evaluating test-taking performance after every turn). Are there new products or ways of using AI that naturally enable us to collect this kind of data?
- Q3: If user specification relies on having information in context, how do we naturally simulate not knowing something? More speculative approaches could involve knowledge editing or training models only on a subset of data.
Scaffold
So far, we’ve discussed what context is necessary to provide a complete specification of a user However, in many cases it’s fundamentally unnatural to provide a user simulator with all the context up front. When booking a hotel, you might only be reminded that you prefer an in-house gym if you see that advertised on one of the options. Human memory looks more like “checking things into context” from long-term memory; the search (or chat interaction) can shape which preferences are revealed.
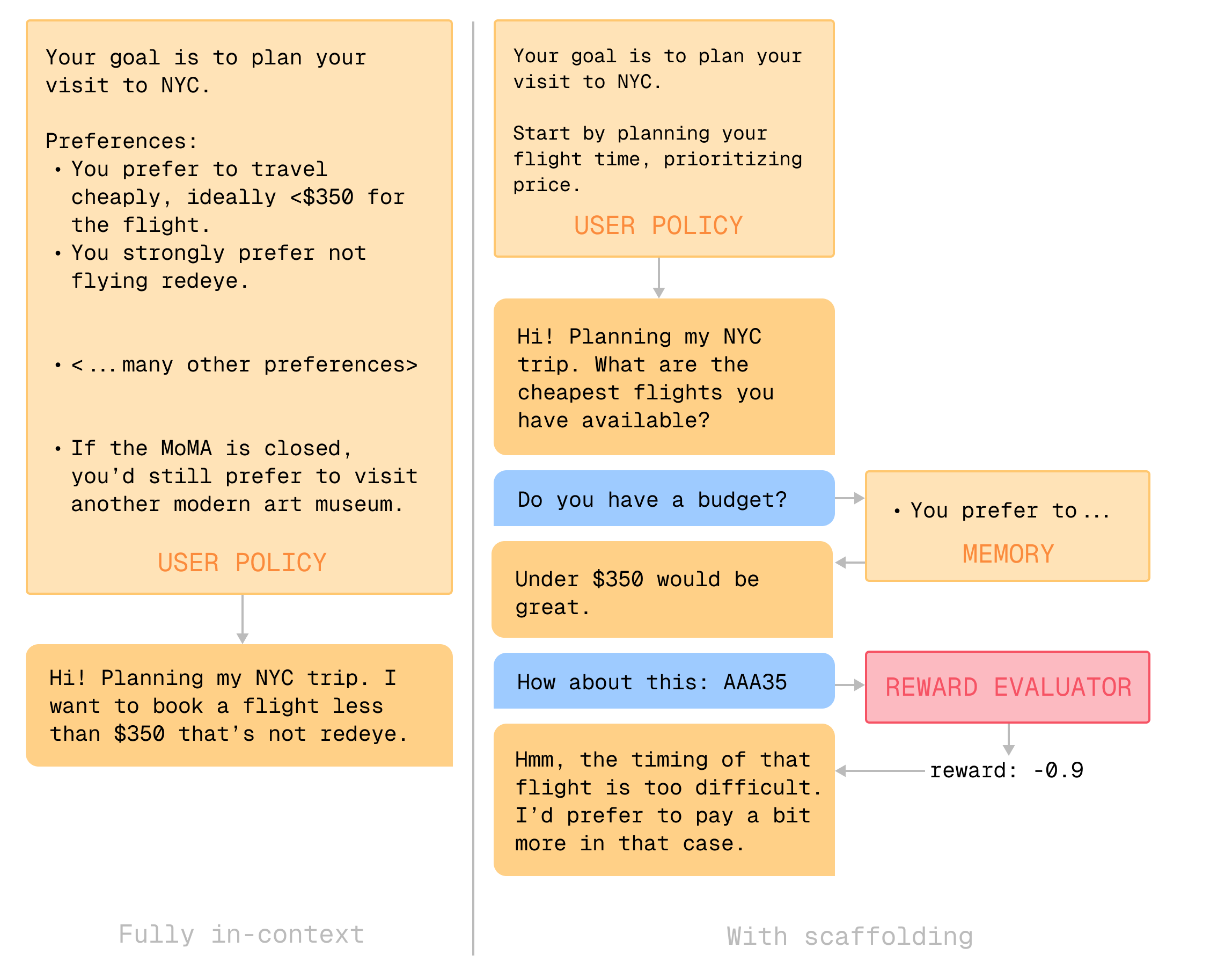
To simulate these aspects of humans, we might turn to scaffolds, which define how an agent interfaces with its environment and context. We can adjust what information the model sees, and how it evolves over time, by modifying the agent scaffold. For example, we can model differences in:
- Goal or information fidelity. While some users might begin an interaction with a fully-specified goal, most users aren’t precise in what they want. We could model this by translating a fully-specified reward function into a fuzzy natural language string like “slight preference for outdoor seating,” without specifying how much or under what conditions the user would be willing to give up outdoor seating. In fact, anything the user knows can be known to different degrees of fidelity.
- Self-knowledge. Intuitively, it’s easier to compare which of two options is better (and then put your finger on why) than to exhaustively recall everything you care about upfront or provide an absolute score in isolation. We could model this by only allowing the policy to call
preferred(option A, option B)but notreward(option A), or by not providing a description of therewardfunction. We experimented with this in DialOp by initializing user simulators with vague preference descriptions and only allowing them to see exact reward values when the assistant provided concrete proposals. - Influence. Interactions influence what users understand and want. For example, I might forget that ambience matters to me until an assistant shows me pictures of the interior of a restaurant. We can model this with a “belief update” function that injects new preferences into context based on the interaction. For domains like education, creating a belief update function that models what the user simulator understands as the dialogue goes on might be a full-fledged problem in itself.
- Memory & cognitive load. To model the fact that humans have limited memory, we can simulate a (primitive) memory mechanism that summarizes earlier parts of the dialogue or pushes them into a long-term memory store. For example, a realistic user simulator might occasionally ask, “I don’t remember the exact details of the earlier proposal you sent me, could you show me that again?” This would disincentivize models that dump information on the user — past a certain point, more information only overwhelms the user, and maybe even results in more errors. The best assistants will take human limitations into account.
Products are already designed to take human “quirks” like these into account. For example, shopping products often default to offering multiple product recommendations, which makes it easier for users to make comparisons. Deep Research always asks 1-2 clarification questions at the beginning of the dialogue, to account for the fact that most prompts aren’t fully specified up front. Chatbot assistants can be post-trained to repeat or summarize what was discussed earlier in the dialogue, accounting for users having limited memory.
One theme here is that the policy doesn’t need to have the same information that the reward model does, even though they represent the same user. Because people don’t know what they want, they don’t always act in accordance with their “true” preferences. An exciting prospect for future assistants is to guide us towards what we actually want, helping us introspect and discover solutions we didn’t consider at first glance — beyond current-day chatbots that just take the first thing we ask for literally.
- Q1: Are there general principles that can guide the design of human-like agent scaffolds? Because there are many axes along which agent scaffolds can vary, we run the risk of building arbitrary decisions into our user simulators. Is it possible to make more principled decisions about, e.g., belief update functions, by modeling the perplexity of or similarity to real human interactions?
- Q2: A scaffold essentially builds in an inductive bias that makes the structure of an agent similar to a human. What inductive biases are actually necessary, vs. easily learnable from data? Is there anything to be gained from what we know about the structure of human thinking, such as when people recall things from long-term memory?
Objective
Scaffolds are a natural extension of the core principle of RL: we can make hard-coded decisions a bit more flexible by embedding what we know about humans into incentives (i.e. properties of the user simulator / environment), letting assistant behavior instead emerge from training. To take this principle to its natural end, perhaps we can also build more human-like user simulators by changing the objective that our models optimize.
To solve issues such as LMs not “really wanting things” (as described in our previous post) , we might want to train user simulators on the (range of) objectives that we think users optimize for.
Users care about completing the task, but optimizing user models naively to complete the task could make them too eager to work together. RLHF-trained models are already “too helpful.” In reality, humans are optimizing for a multitude of objectives, even in the course of doing a well-scoped task: Alice, who wants to expend the least amount of effort possible; Timmy, who’s indecisive and also considering the objectives of other people in his group; Oliver, who doesn’t settle for satisficing and wants the absolute best option.

There are well-understood universalities to human psychology such as loss aversion, making perceived values more asymmetric than those assessed objectively by a computer or LM. Building user simulators that pursue goals in the ways humans do might look to prospect theory or other formalizations of how utility distributions, probabilities, and the rest of the computational world map to perceived human value.
We might also want to model users with adversarial objectives. Reliability testing is one use case for user simulators, where it feels natural to train users that probe for edge cases and failure modes in the assistant’s policy. User simulation is another lens to view what some are already doing to audit language model behavior at scale.
Training user models to optimize the objectives that users have may not be enough in some cases. Consider the work on training human-like bots for Chess or Go. There, it’s well-established that behavior cloning on human data isn’t enough1. On the other hand, optimizing directly for the task objective through inference-time search (e.g., Deep Blue) or self-play training (AlphaZero) can match or exceed human performance, but result in qualitatively different behavior.
Instead, a set of hybrid approaches combine the best of two worlds: piKL directly trained models on a task objective, while simultaneously minimizing KL divergence from a behavior cloned policy, leading to more human-like gameplay in chess and Go. A variant of piKL was used in Cicero, the first model to obtain superhuman performance in Diplomacy, as part of its planning loop. Alternatively, we can impose cognitively-inspired resource constraints on the optimization process. For example, Zhang, et al. (2024) showed that limiting the amount of inference-time search models can conduct, akin to limited planning depth in humans, can result in more human-aligned chess bots. We can imagine applying some of these same ideas to user simulation with language models.
- Q1: When is training user models with objectives worth the complexity over collecting more human data? Are there cases where it gets us qualitatively different behaviors? The main benefit of using objectives is emergent, large-scale diversity from a single specification (e.g. the user's degree of loss aversion can be a single hyperparameter). The simpler approach is just to train on more human data, but the verdict is still out on whether this is sufficient. Training models on increasingly large datasets of human interactions and developing a “scaling law for user simulators” could be a first step to determining whether data- or objective-centric approaches are more scalable.
- Q2: Does modeling human cognition improve user simulators? One interesting experiment would be to build a series of user simulators with different cognitive biases, train assistants for each of them in self-play, and evaluate emergent properties of the trained models. For example, does training against user models with limited “attention spans” result in more communicatively efficient assistants?
Of course, there are many more open questions: what’s the best way to evaluate user simulators? Once we build high-quality user simulators, what’s the best way to actually train and improve our assistant models? How can we train models that generalize to real humans, and don’t just overfit simulated users? And finally: when are user simulators most useful, compared to other recipes such as iterative deployment, offline data, or online learning with real people? We think that tackling these questions will be an important step toward building more useful, collaborative LMs.
We’re actively working on building better user simulators and training models against them. If you’d like to chat, please reach out to us!
If you’d like to cite this post:
@misc{lintomlin2025usersimpart2,
author = {Jessy Lin and Nick Tomlin},
title = {What does it take to build a human-like user simulator?}
howpublished = {\url{https://jessylin.com/2025/09/26/user-simulators-2/}},
}
-
Multiple empirical results have shown how imitation learning requires huge amounts of data (e.g. 15B datapoints) and still fail to match or improve as quickly as the humans who generated the training data. ↩